WSL2をWSL1に変更する
きっかけ
WSL2でviteを使って開発していたのですが、しばらく立ち上げているとHMRが応答せずWSLを落とさなければならない、ということが頻発していました。
開発環境としては、
- ファイルそのものはWindowsOS側で管理
- エディターはVSCodeやRiderなどWindowsOS側のアプリケーション
- しかし、vite自体はWSLで動作させたい
という状態です。つまり、WindowsOS側とWSLでファイルを相互に見合っていました。
改めて調べてみると「ファイルを相互に見合う状態」はWSL1を使った方がよいというユースケースに当てはまりそうなため、WSL1に戻すことを試してみました。
WSL2からWSL1にバージョンを落とす
まずWSLのバージョンを確認します。
$ wsl -l -v NAME STATE VERSION * Ubuntu-22.04 Running 2
WSL2になっていますね。
WSLのデフォルトバージョンと、変更したいディストリビューションをそれぞれ WSL1 にします。
$ wsl --set-default-version 1 $ wsl --set-version [ubuntu_name] 1 => 自分の環境では $ wsl --set-version Ubuntu-22.04 1
再起動します。
$ wsl
本来はこの時点で無事WSL1になった状態で立ち上がるようですが、自分の場合は以下のエラーが出てうまくいきませんでした。
<3>WSL (11) ERROR: CreateProcessEntryCommon:577: execvpe /home/linuxbrew/.linuxbrew/bin/zsh failed 14
どうやらzshが影響していそうです。
ということでWSL2に戻してから shell を bash にし、改めてWSL1に変更します。
... 先ほどのWSL1にした手順と同様にバージョンを2にする ... $ sudo chsh $USER -s $(which bash) ... 先ほどのWSL1に変更する手順をもう一度実行 ... $ wsl
これで無事起動しました。
ただ、WSL1になった状態でshellをzshに変更するとまた同様のエラーが出たので、bashのままにしています。
WindowsにおけるWebフロントエンド開発は「ファイルをWindowsOSとWSLで相互に見合う」状態になることは珍しくないと思うので、WSL2においてファイルシステム管理の問題が残り続ける限りはWSL1のままにしておくのが安全そうです。
【WebGL2】threejs で Deferred Shading

リポジトリとデモはこちらになります。
https://takumifukasawa.github.io/threejs-deferred-shading/base.html
https://takumifukasawa.github.io/threejs-deferred-shading/point-light.html
https://takumifukasawa.github.io/threejs-deferred-shading/post-process.html
WebGL2がiOS15から有効になり、WebGL1までは拡張機能となっていた MRT(Multiple Render Target)が標準機能になりました。
MRTを使って実現しやすくなることの中に、DeferredShadingが含まれます。今回はthreejsでDeferredShadingを実現する方法を探りました。
threejsを使うことにしたのは、仕事を踏まえてどれぐらい使えそうかも確認したい展望もあったためです。
Deferred Shading
解説している記事がたくさんあるので、ここでは簡単に説明を記載します。こちらの記事がわかりやすいです。
【Unity】Deferred Shadingでライトを贅沢に使いたい!基本的な概念の説明とメリデメを考察 - LIGHT11
ディファードレンダリングだったり、遅延シェーディングと呼ばれたりもします。ここでは、 Deferred Shading と呼ぶことにします。
古典的なレンダリング方法である Forward Shading ではポリゴンを描画する際にライティングなどを加味した色も計算します。つまり、ポリゴン(メッシュ)が描画されるごとに色を決定していく方法です。 一般的にはこちらが使われていますね。
Deferred Shadingでは、ポリゴンを描画する際に色を決定する方法はとらず、深度や法線など色を決定するのに必要な情報群をバッファ群(G-Buffer)に一度格納し、そのバッファを元にライティングなどの色を決定させていく方法です。
G-BufferはGeometry Bufferと呼ばれます。メッシュのジオメトリ情報(法線やカラーなど)を格納するバッファです。後述しますが、G-Bufferに入れる情報は自分で定義することができるので、ジオメトリ情報に限らずデータを入れていくことが可能です。
メリット
Forward Shadingと比べて、多数のライトを置けること、ポストプロセスでG-Bufferの情報をあつかうことができる点です。SSAOやSSRは導入しやすくなるでしょう。
デメリット
半透明描画はG-Bufferの色の計算のあとに行う必要があるので結局ForwardShadingを使うことになり複雑になる点です。
また、ポストプロセス的にピクセル数分ライティングの計算が走るので計算負荷がかかりすいこと、マテリアルの種類が多くなればなるほシェーダー内での分岐が必要になる・それがピクセル数分の計算になるためシェーダーが重くなりやすいことも欠点の内かなと思います。
threejsでMRT
MultipleRenderTarget というクラスが用意されているのでそちらを使ってみます。
three.js webgl - Multiple Render Targets
ただ、中身を見るとRGBA32bit以外のフォーマットは選ぶことができないようになっていたので必要なG-Bufferの情報に合わせて自分で似たような仕組みを作ってあげてもよいと思います。
G-Bufferに入れる情報
G-Bufferの中身は自分で定義することができます。つまり、アプリケーションごとに異なるということですね。
今回は2枚用意します。格納する情報は以下です。
index 0: RGBA32bit(RGB: メッシュの色、A: マテリアルのインデックス) index 1: RGBA32bit(RGB: ワールド座標系の法線情報を0-1に変換したもの、A: 1
深度情報は MultipleRenderTarget.depthTexture でアクセスできるのでそちらを使います。
法線情報をワールド座標系にしているのはワールド座標基準でライティングを計算することに決めたためです。正規化された法線はxyzが-1~1に収まるので、0~1に直しておく点がポイントです。
MultipleRenderTargetsからMRTのテクスチャを渡すためには、textureが配列になっているのでuniformと紐づけて渡します。
const gBufferPaths = [ { name: "diffuse", }, { name: "normal" }, ] // サイズは後で変更 const renderTarget = new THREE.WebGLMultipleRenderTargets(1, 1, gBufferPaths.length); renderTarget.texture.forEach(texture => { texture.minFilter = THREE.NearestFilter; texture.magFilter = THREE.NearestFilter; }); gBufferPaths.forEach((({ name }, i) => { renderTarget.texture[i].name = name; })); ... const postprocessMaterial = new THREE.RawShaderMaterial({ vertexShader: renderVertexShaderText, fragmentShader: renderFragmentShaderText, uniforms: { uDiffuse: { value: renderTarget.texture[0] }, uNormal: { value: renderTarget.texture[1] }, uDepth: { value: renderTarget.depthTexture, }, ...
MRTに情報を書く
Forward Shadingではピクセルシェーダーで出力するのは「0-1で表現された色」になります。
対してDeferred Shadingではピクセルシェーダーで各バッファに出力する情報群を書きだします。
生WebGLでの実装はwgld.orgの記事が分かりやすいです。
wgld.org | WebGL: MRT(Multiple render targets) |
こちらは実際に今回書いたG-Bufferにデータを格納するピクセルシェーダーです。
本来は色だけを出力しているところが、out修飾子のついているgColorとgNormalの二つに値を渡していることがわかると思います。
precision highp float; precision highp int; layout(location = 0) out vec4 gColor; layout(location = 1) out vec4 gNormal; in vec3 vNormal; in vec2 vUv; uniform float uMaterial; uniform vec3 uBaseColor; void main() { gColor = vec4(uBaseColor, uMaterial); vec3 normal = (normalize(vNormal) + 1.) * .5; gNormal = vec4(normal , 1.); }
shading
ワールド座標
いよいよG-Bufferを元に色を決定していきます。G-Bufferや深度テクスチャを元に、法線・色・深度の情報はすでに揃っています。
しかし、ワールド座標基準でのライティングにはまだ足りないものがあります。それは該当ピクセルのワールド座標です。
G-Bufferに格納することも可能ですが、それではG-Bufferのバッファが一枚増えることになるので負荷も上がります。
ここでは、以下のようなシェーダーで深度からワールド座標を復元する方法をとります。
// depth: depth buffer から読みだした値をそのまま渡す vec3 getWorldPositionFromDepth(vec2 uv, float depth) { vec4 ndc = vec4(uv * 2. - 1., depth * 2. - 1., 1.); vec4 wp = uInverseViewMatrix * uInverseProjectionMatrix * ndc; wp.xyz /= wp.w; return wp.xyz; }
やっていることは以下です。
ライティング計算
必要な情報が揃ったらライティングを計算します。疑似的なコードになりますが、最も単純なのはライトの数分ループを回しライティングを計算する方法です。
vec4 color; ... for(int i = 0; i < lightNum; i++) { PointLight pointLight = uPointLights[i]; color += calcPointLight(pointLight, surface, camera); // ポイントライトの数だけライティングの影響を計算をする }
改善
画像のようにアーティファクトが出ています。どういう原因なのかがまだつかめていないのですが、隣接ピクセルが、他のポリゴンのピクセルが存在しないピクセルの場合、1pxだけ白くなってしまっています。
おそらくthreejsのrendererの設定かシェーダーの精度などが原因のように推察しているのですが、まだ未解決です。

参考
three.js webgl - Multiple Render Targets
three.js/WebGLMultipleRenderTargets.js at master · mrdoob/three.js · GitHub
three.js webgl - Depth Texture
G-Buffer の深度値からワールド空間の位置を復元した秋 2016 - Engine Trouble
opengl - GLSL Light (Attenuation, Color and intensity) formula - Game Development Stack Exchange
【Unity】Screen Space Reflection のカスタムポストプロセスを forward rendring で実装

ポストプロセス的に反射表現を実現する方法である Screen Space Reflection を実装してみました。
サンプルリポジトリはこちらになります。
環境
Unity 2021.3.23f1 built-in pipeline
forward rendering
前段
リアルタイムレンダリングのラスタライズ法において反射は、特に負荷のかかりやすく工夫のいる表現の代表例だと思います。視点に依存したり、周囲の環境による部分が大きいですからね。「周りの写り込み」が入ることによって圧倒的に情報量と説得力が増しますが、どこまで反射を表現するかによってとる方法が大きく変わります。
「周囲の環境を踏まえた反射色の決定」の実現でまず思いつくのは、環境マップです。なんとなく反射の情報量を増やしたい場合は環境マップで事足りるケースが多いと思います。しかし、環境マップに「動くもの」も含めるのは骨が折れます。端末のスペックが十分であれば環境マップをリアルタイムに生成し続けることで実現できます。しかし、特にモバイルではスペックが足りず厳しいでしょう。
また、解像度感も問題になります。綺麗な環境マップを生成するには解像度を高くすればよいのですが、環境マップ用に周囲の6面をテクスチャに焼き、環境マップを生成し...という過程を経るのでやはりランタイムでは相当な負荷が予想されます。負荷を考えると解像度は低くするべきですが、鏡面反射に近いようなマテリアルでは解像度不足感が否めない可能性があります。
Screen Space Reflection も高負荷な処理の一つですが、ポストプロセス的なアプローチで「動くもの」を反射に加えることができます。
実装
下準備
シーンの深度情報と法線方向の情報、色情報が必要です。deferred rendring は G-Buffer から法線などを参照することが可能ですが、builtin-pipeline の forward rendering の場合は一工夫が必要です。
具体的にはdepthTextureModeを操作し、シェーダー内で深度と法線情報を取得できるようにします。
_camera.depthTextureMode |= DepthTextureMode.DepthNormals;
https://docs.unity3d.com/Manual/SL-CameraDepthTexture.html
これを設定すると、テクスチャに深度と法線が一まとめに格納されます。frame debugger に表示されている UpdateDepthNormalsTexture が深度・法線をテクスチャに書き込んでいくパスです。
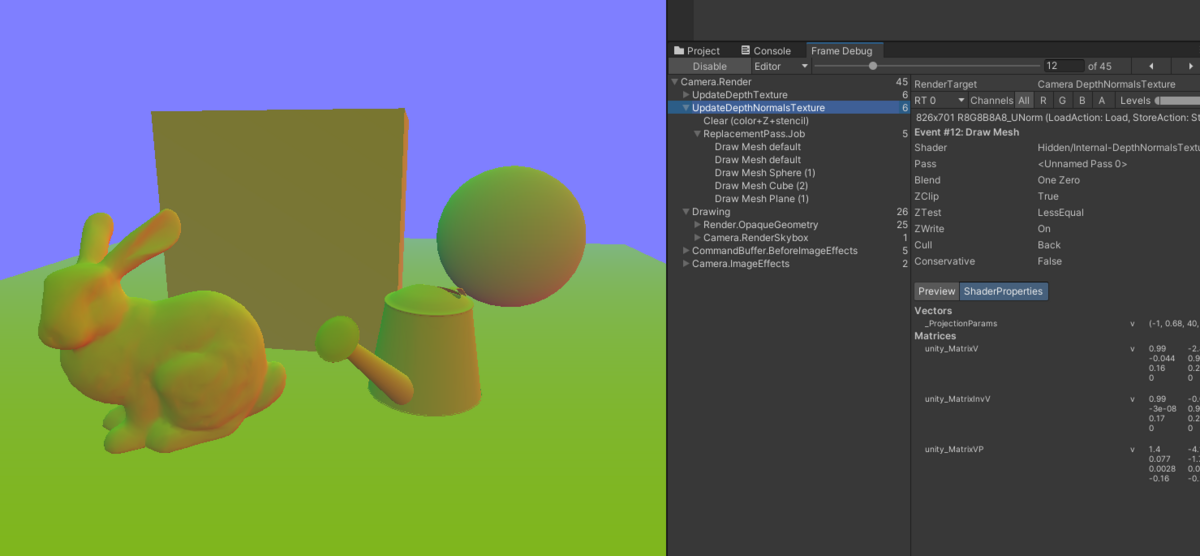
DepthNormalなテクスチャをシェーダー側からデコードして深度と法線を取り出すコードは下記です。深度は線形化されたもので、法線はビュー座標系になっています。
プロジェクトでは、デコードする関数の一部をUnityCG.cgincから参照してきています。UnityCG.cgincを参照していればこの関数の記述は必要ありません。
...
TEXTURE2D_SAMPLER2D(_CameraDepthNormalsTexture, sampler_CameraDepthNormalsTexture);
...
// ------------------------------------------------------------------------------------------------
// ref: UnityCG.cginc
// ------------------------------------------------------------------------------------------------
float DecodeFloatRG(float2 enc)
{
float2 kDecodeDot = float2(1.0, 1 / 255.0);
return dot(enc, kDecodeDot);
}
void DecodeDepthNormal(float4 enc, out float depth, out float3 normal)
{
depth = DecodeFloatRG(enc.zw);
normal = DecodeViewNormalStereo(enc);
}
...
float depth = 0;
float3 viewNormal = float3(0, 0, 0);
float4 cdn = SAMPLE_TEXTURE2D(_CameraDepthNormalsTexture, sampler_CameraDepthNormalsTexture, i.texcoord);
DecodeDepthNormal(cdn, depth, viewNormal);
レイを飛ばす
まずピクセルごとに、視点からジオメトリの座標までのベクトルを算出し、法線方向に反射したベクトルを求めます。
「ジオメトリの座標」はワールド座標でも、ビュー座標でもクリッピング座標でも問題ありません。任意の座標系で実装します。サンプルでは、後述するフェードの実装のしやすさなどの関係でビュー座標系を基本とします。
次に、反射したベクトル方向に、等距離ずつサンプル点を移動させていきます。レイマーチングやレイトレに馴染みのある方だと「反射方向にレイを進めていく」という表現が分かりやすいかなと思います。
レイを進めていきながら、「カメラから描画されたジオメトリまでの距離(青の点)」と「レイの位置までの距離(赤の点)」を比較します。
青の点が赤の点よりもカメラに近い場合、「反射してぶつかった場所」とみなします。
そして、反射してぶつかった場所の色をサンプルし、加算などブレンドをします。図ですと、青い点の中の一番上のものを反射で写りこむ色として捉えます。
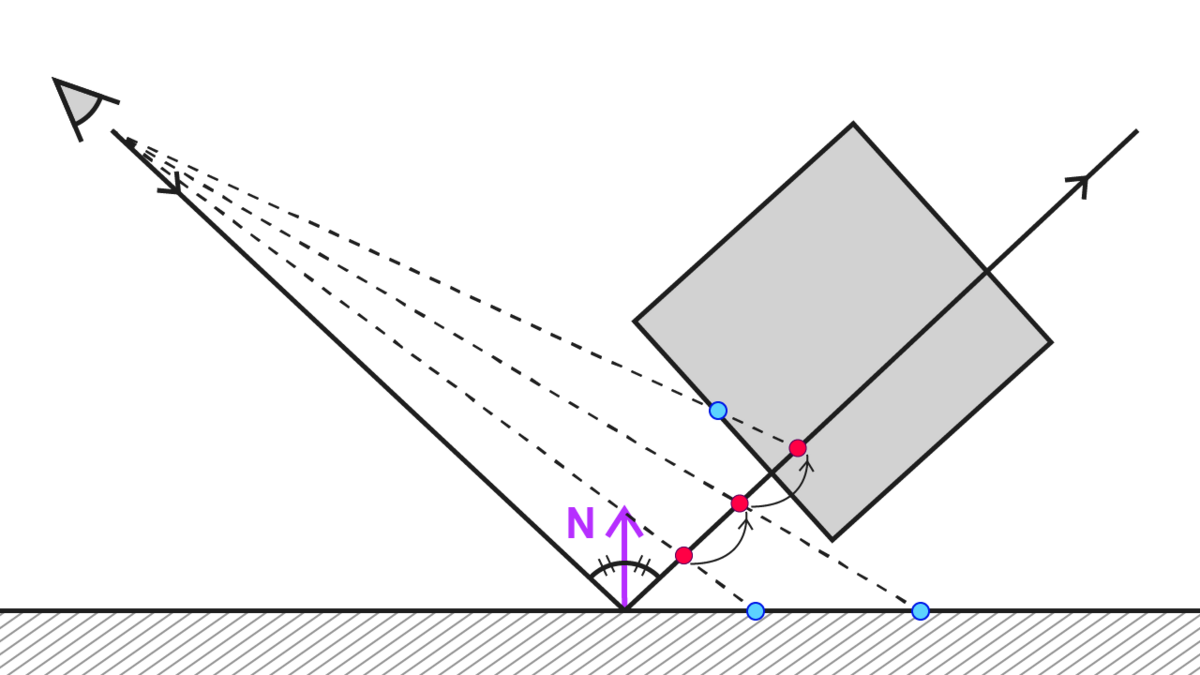
厚みを考慮する
見た目の精度を高めていく実装です。
前述のように「カメラから描画されたジオメトリまでの距離」と「レイの位置までの距離」を比較し前者の方が近ければ反射とみなすのですが、大きな問題が一つあります。
それは、この2つの距離が離れすぎているケースです。
近いかどうかだけを判断している場合、極論ですがカメラからジオメトリまでの距離が10m、カメラからレイの位置までが10000mとしたら、それも反射色をサンプルする対象になってしまいます。そのため、シーンによっては違和感のある反射が生まれます。
なので、レイとジオメトリまでの距離も考慮し、反射でぶつかったとみなす範囲を制限する実装にしてみます。例えば距離が0.1~5mまでの範囲内であれば反射してぶつかったとみなす、という具合ですね。
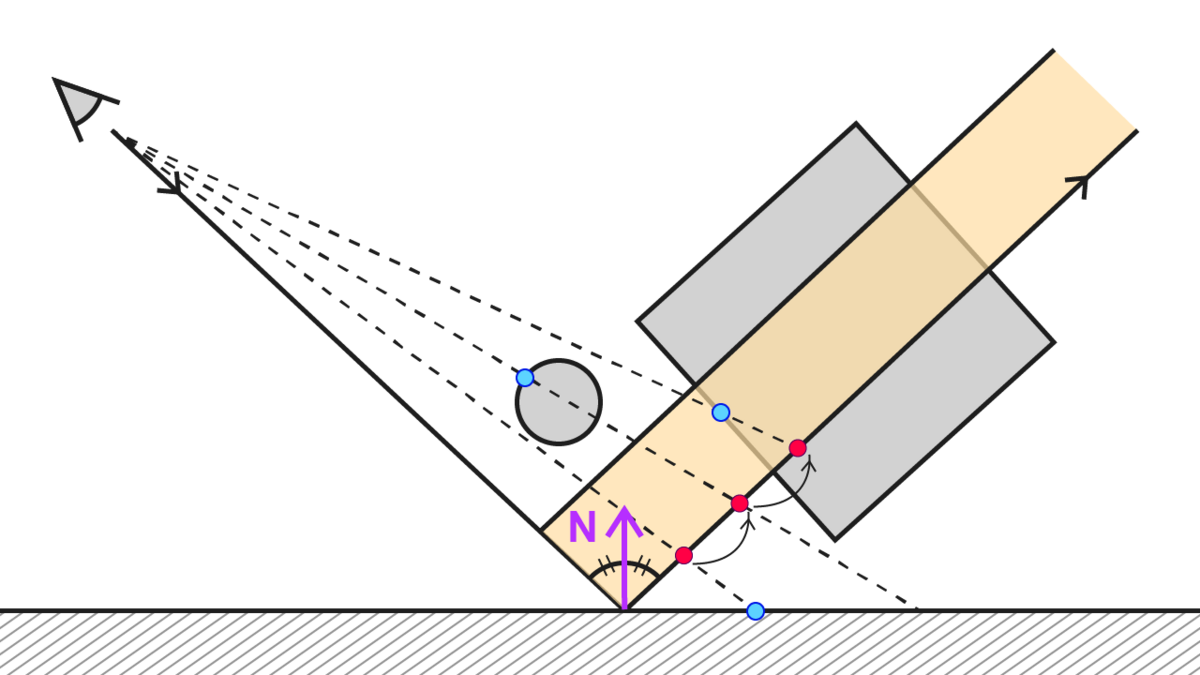
...
for (int j = 0; j < maxIterationNum; j++)
{
float stepLength = rayDeltaStep * (j + 1 + jitter * _ReflectionRayJitterSize) + _RayNearestDistance;
currentRayInView = rayViewOrigin + rayViewDir * stepLength;
float sampledRawDepth = SampleRawDepthByViewPosition(currentRayInView, float3(0, 0, 0));
float3 sampledViewPosition = ReconstructViewPositionFromDepth(i.texcoord, sampledRawDepth);
float4 currentRayInClip = mul(_ProjectionMatrix, float4(currentRayInView, 1.));
currentRayInClip.xyz /= currentRayInClip.w;
// クリッピング座標の外に出たら棄却
// zは一旦考慮しない
if(abs(currentRayInClip.x) > 1. || abs(currentRayInClip.y) > 1.)
{
break;
}
float dist = sampledViewPosition.z - currentRayInView.z;
if (_RayDepthBias < dist && dist < _ReflectionRayThickness)
{
isHit = true;
break;
}
}
...
thickness off

thickness on

二分探索(バイナリサーチ)
いわゆるバイナリサーチの考え方の応用になります。レイを少しずつ進めていく実装では精度は「レイを進める回数」「進む間隔(ステップ)」に大きく依存します。しかし、精度を上げようとすればするほど計算が重くなります。たとえば64回レイを進めながら反射しているかどうかを確認する場合、1280x720の画面だったとしたら 1280x720x64 = 58982400 回分の探索が毎フレームで発生する計算になります。
また、ステップの間隔が広すぎるとマッハバンドのような段々が出来てしまいます。かといって、狭すぎると近い距離までの反射しか考慮できないので、物足りなさがあります。
そこで、バイナリサーチを使って探索回数を最適化していきます。実装としては、等距離で進む部分は変わりませんが、ヒットした場合に反射の色のサンプル位置をより詳細に探っていきます。
「大まかにステップを進め」、「ヒットしたら詳細に探索をしていく」ようなイメージです。
図のような手順を踏みます。
ヒットしたらバイナリサーチを開始。ステップ間隔を半分にして戻る
ヒットしたかどうか確認
ヒットしたらステップ感覚を半分に戻る / ヒットしなかったらステップ間隔を半分にして進む
2,3を任意の数繰り返す
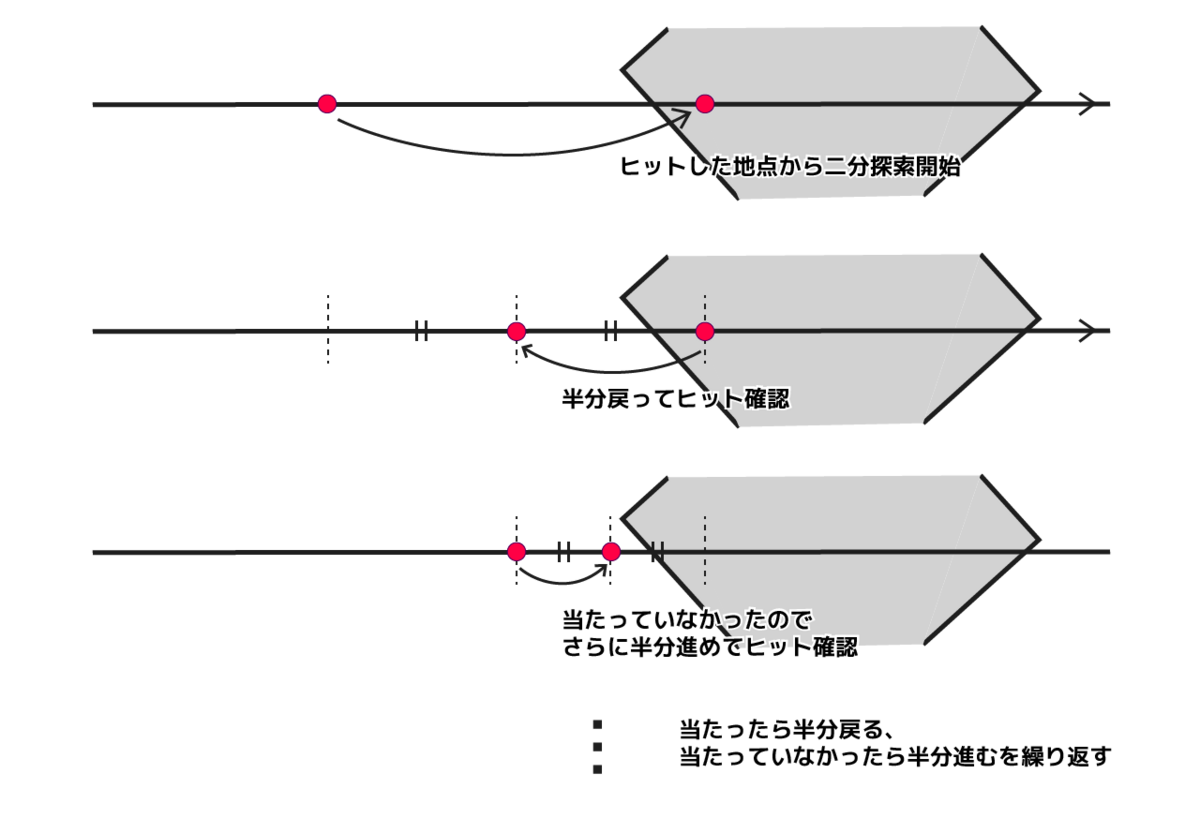
こうすることで、大まかなステップを30回・詳細なステップを8回とすると、レイを進める回数は30+8で38回になります。バイナリサーチを使うことで、レイを進める回数を減らしつつ段々になってしまう間隔を多少狭くすることができます。
if (isHit) { // stepを一回分戻す currentRayInView -= rayViewDir * rayDeltaStep; float rayBinaryStep = rayDeltaStep; float stepSign = 1.; float3 sampledViewPosition = viewPosition; for (int j = 0; j < binarySearchNum; j++) { // 衝突したら半分戻る。衝突していなかったら半分進む // 最初は stepSign が正なので半分進む rayBinaryStep *= 0.5 * stepSign; currentRayInView += rayViewDir * rayBinaryStep; float sampledRawDepth = SampleRawDepthByViewPosition(currentRayInView, float3(0, 0, 0)); sampledViewPosition = ReconstructViewPositionFromDepth(i.texcoord, sampledRawDepth); float dist = sampledViewPosition.z - currentRayInView.z; stepSign = _RayDepthBias < dist ? -1 : 1; } float4 currentRayInClip = mul(_ProjectionMatrix, float4(currentRayInView, 1.));
binary search off

binary search 8 times

jitter
バイナリサーチを使ってレイを飛ばす回数の最適化をしても、レイを飛ばす間隔に依存してマッハバンドのような段差の軽減は限界があります。そこで、レイを飛ばすときにレイの方向をちょっとずらして散らすことで、精度が低く感じる見た目を軽減させます。
レイトレーシングでは重点サンプリングをするために飛ばすレイを散らすことでノイズ軽減をする方法がありますがそのイメージが近いです。
また、ちょっとしたブラー的な効果を得ることができます。
欠点は、時間依存でランダムにノイズを足そうとするとカメラが止まっているときでもノイズが走り続けているような見た目になることです。カメラが止まっているときはノイズの散らし方を変えないようにしたり、後述するような平均化を行うと軽減されるはずです。
float noise(float2 seed) { return frac(sin(dot(seed, float2(12.9898, 78.233))) * 43758.5453); } ... float jitter = noise(i.texcoord + _Time.x) * 2. - 1.; float2 jitterOffset = float2(jitter * _ReflectionRayJitterSizeX, jitter * _ReflectionRayJitterSizeY); for (int j = 0; j < maxIterationNum; j++) { float stepLength = rayDeltaStep * (j + 1) + _RayNearestDistance; currentRayInView = rayViewOrigin + float3(jitterOffset, 0.) + rayViewDir * stepLength; ...
jitter off

jitter on

画面端のフェード
反射した先の色は、シーンの色情報を元に算出します。つまり、もともとカメラの範囲に入っていないものを反射の色に含めることはできないという欠点があります。 そのためシーンの構成によっては画面の端の反射が違和感に感じる場合があるので、画面の端にいくほど反射をフェードアウトさせるようにしてみます。
// screen edge fade float screenEdgeFadeFactorX = (abs(i.texcoord.x * 2. - 1.) - _ReflectionScreenEdgeFadeFactorMinX) / max(_ReflectionScreenEdgeFadeFactorMaxX - _ReflectionScreenEdgeFadeFactorMinX, eps); float screenEdgeFadeFactorY = (abs(i.texcoord.y * 2. - 1.) - _ReflectionScreenEdgeFadeFactorMinY) / max(_ReflectionScreenEdgeFadeFactorMaxY - _ReflectionScreenEdgeFadeFactorMinY, eps); screenEdgeFadeFactorX = saturate(screenEdgeFadeFactorX); screenEdgeFadeFactorY = saturate(screenEdgeFadeFactorY); screenEdgeFadeFactorX = 1. - screenEdgeFadeFactorX * screenEdgeFadeFactorX; screenEdgeFadeFactorY = 1. - screenEdgeFadeFactorY * screenEdgeFadeFactorY;
反射距離でのフェード
本来、素材によって映り込みの見た目が変わります。SSRにおいて、反射の範囲が広いと鏡面反射のような素材感に見える場合があるので、ジオメトリの座標とレイの距離に応じてフェードするようにしてみました。
deferredであればsmoothnessなど、マテリアルの素材に関わるようなパラメーターに応じてフェード具合などを調整するなどしてもいいかもしれません。
float rayWithSampledPositionDistance = distance(viewPosition, sampledViewPosition);
float distanceFadeRate = (rayWithSampledPositionDistance - _ReflectionFadeMinDistance) / max(
_ReflectionFadeMaxDistance - _ReflectionFadeMinDistance, eps);
distanceFadeRate = saturate(distanceFadeRate);
distanceFadeRate = 1. - distanceFadeRate * distanceFadeRate; // 距離減衰
画面端のフェード・反射地点の距離フェードなし

画面端のフェード・反射地点の距離フェードあり

SSRの欠点
ます、高負荷になりがちです。深度、法線情報が必要になり、精度を上げるためにはレイを飛ばす回数を増やす必要があるのが大きな理由です。
見た目的に大きな欠点は「裏側」を描画することができない・画面端のようにもともとカメラに映っていないものは反射に含めることができない、という点です。
裏側に関しては、カメラに映らない裏側が見える位置に別のカメラを置きRenderTextureに描画し、裏側の色を反射した先の色としてみなす場合はそのRenderTextureを参照するという方法も考えられますが、 Screen Space Reflection の基本的な実装部分の負荷がすでに高めになりがちなので、端末スペックやパフォーマンスに余裕があるときでないと採用は難しいはずです。
改善
今回は「ポストプロセスのパス」で計算する方法をとりました。実用をさらに踏まえると、
フル解像度ではなく1/2ぐらいの縮小バッファを使うことによる速度改善
複数フレーム間での平均化やブラーを入れることによる品質改善
が見込めるので、RenderTextureを使って計算する方がよいかもしれません。
参考
https://tips.hecomi.com/entry/2016/04/04/022550
https://zenn.dev/mebiusbox/articles/43ecf1bb12831c
http://www.kode80.com/blog/2015/03/11/screen-space-reflections-in-unity-5/
https://hanecci.hatenadiary.org/entry/20140617/p8
【Unity】Screen Space Ambient Occlusion のカスタムポストプロセスの実装

デモのgitはこちらです。
環境はこちらです。
Unity 2021.3.26f built-in pipeline
色も調整できるようにしてみています。

現実とリアルタイムグラフィクスの壁
Ambient Occlusion は直訳すると「環境遮蔽」です。
室内に目を向けると、天井と壁の継ぎ目の隅はちょっと暗くなっています。大雑把な理由は「光が届きにくいから」です。しかしこれがリアルタイムグラフィックスだととても厄介なものになります。
レイトレーシングやいわゆるシェーダー芸のレイマーチングはある程度光学的に正しいアプローチをとることができるので再現しやすいのですが、ラスタライズ手法の Forward Rendering, Deferred Rendering では再現に一苦労します。
それは、 Forward Rendering や Deferred Rendering のライティングは、どちらも基本的には「周囲のオブジェクト」は考慮しないものになっているからです。
forward rendering では一個一個のオブジェクトを塗る時に、そのオブジェクトと光源の情報から色を決定させているからです。deferred rendering はポストプロセス的にG-Bufferを用いてライティングを考慮した色を計算していますが、「周囲のオブジェクト」を考慮しないライティング計算になっている点は同じです。
しかし、直接光がもたらす影など陰影はオブジェクト同士の関係性の認識に大いに役立ちます。近距離にあるオブジェクト同士がもたらす影は、距離感の把握やリアリティさの向上につながります。
SSAO (Screen Space Ambient Occlusion)
そこで登場するのが Screen Space Ambient Occlusion、通称SSAOです。文字の通り、スクリーンスペース(ポストプロセス)のアプローチで環境遮蔽を実現する方法です。
利点は動く物体にも適用できる点です。あらかじめBakeしている必要がありません。
欠点は、品質を求めれば求めるほど負荷が高くなりやすい点です。
その歴史はこちらのリンクがとてもわかりやすいです。ここ十数年ぐらいの話なんですね。
https://ambientocclusion.hatenablog.com/entry/2013/10/15/223302
今回は、3種のSSAOの根本的な実装をやってみました。
- CryEngine2 の SSAO(全球サンプリング)
- StarCraft II の SSAO(半球サンプリング)
- UE4 の SSAO(Angle Based)※ Angle Based という名前が一般的かは不明
今回は実装していないのですが、本来は見た目の品質を綺麗にするためにAmbientOcclusionを計算した後にバイラテラルフィルターなどを使ってエッジのぼかしをかける場合が多いようです(Angled Based の場合はなくてもよい?)。ぼかすことによってAmbientOcclusionが効いているように見える範囲を広げることによって遮蔽の見た目をより強調する、という意味もあるかもしれません。
SSAOの原理的な部分を知りたかったため、ぼかし関連の品質向上的な処理は省いています。
ちなみにぼかし処理は基本的に重くなりやすいです。例えば縦横5px幅ずつのガウシアンブラーフィルターはそれだけで 10 * 2 + 1 = 21回テクスチャサンプリングが走ってしまいます。そのため特にスクリーンスペースでぼかしをかける場合は注意が必要です。
また、「環境遮蔽」なので環境光にたいしてのみAO項を考慮するのが本来は正しいのですが、今回は Forward Rendring での実装なので環境光にのみAO項を作用させるのが難しいため、シーンの色と環境遮蔽によってもたらされる陰の色をブレンドするようにしています。
1. CryEngine2 の SSAO(全球サンプリング)

「depth bufferを元に、とある点の周囲にどれぐらい遮蔽するものがあるか」を判断する手法です。
自分はビュー座標系を基準にして実装しました。
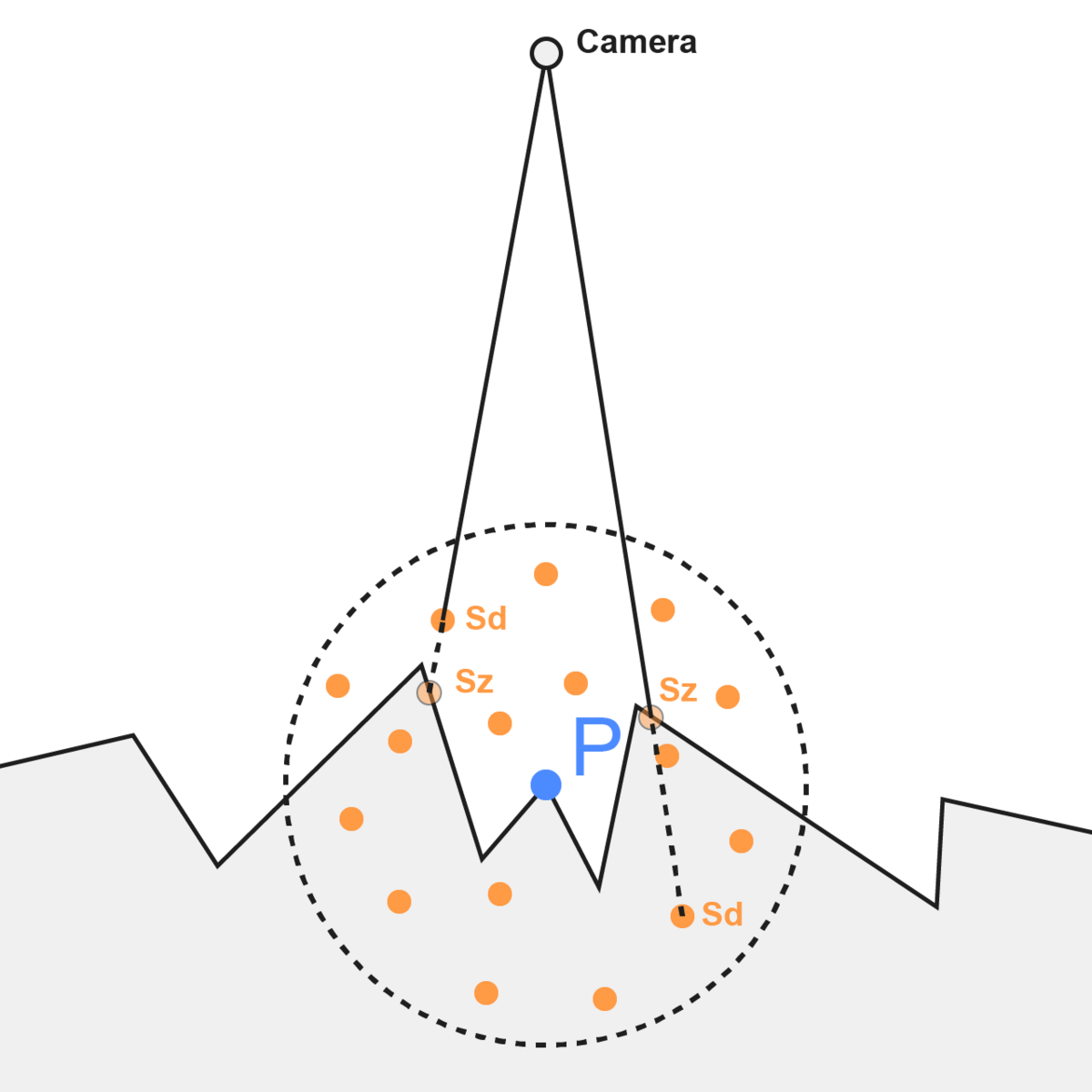
- depth buffer を元に、これから描画する点 P のビュー座標系における位置を求める
- 点 P から、点 P を中心とする全球内のランダムな点 S のビュー座標を計算
- 点 S の深度値(Sz)と、カメラから見た S の位置の depth buffer の深度値(Sd)を比較
- Sd > Sz なら点 S は遮蔽されているとみなす(ex. 画像の右の点)
- 1~4を指定したサンプル数繰り返し、遮蔽率を計算
この方法の利点は、depth buffer さえあれば計算可能な点です。
欠点は、必要なサンプリング数が多くなりやすい(無駄なサンプリングが多くなりやすい)点です。今回のようなシンプルなシーンでは64個ぐらいでもある程度それっぽくなるのですが、複雑な形状のシーンの場合はもっとサンプル数が必要になるでしょう。いずれにしても、スペックの低いモバイル端末だとサンプル数64個でも厳しい可能性があります。
また、わりと全体的に暗くなりがちな点も欠点の一つでしょうか。
以下、該当するc#とシェーダーへのリンクです。
https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Shaders/SSAO.shader https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Scripts/SSAO.cs
実装を一部抜粋しながら見ていきます。
とある点のビュー座標系における位置はdepthから復元することができます。
float3 ReconstructViewPositionFromDepth(float2 screenUV, float depth) { float4 clipPos = float4(screenUV * 2.0 - 1.0, depth, 1.0); #if UNITY_UV_STARTS_AT_TOP clipPos.y = -clipPos.y; #endif float4 viewPos = mul(_InverseProjectionMatrix, clipPos); return viewPos.xyz / viewPos.w; } ... float3 viewPosition = ReconstructViewPositionFromDepth(i.texcoord, rawDepth);
サンプル数分のループ内で、「復元したビュー座標系における位置からランダムにずらした点」のクリッピング座標を求めます。
for (int j = 0; j < SAMPLE_COUNT; j++) { float4 offset = _SamplingPoints[j]; offset.w = 0; float4 offsetViewPosition = float4(viewPosition, 1.) + offset * _OcclusionSampleLength; float4 offsetClipPosition = mul(_ProjectionMatrix, offsetViewPosition); #if UNITY_UV_STARTS_AT_TOP offsetClipPosition.y = -offsetClipPosition.y; #endif float2 samplingCoord = (offsetClipPosition.xy / offsetClipPosition.w) * 0.5 + 0.5; float samplingRawDepth = SampleRawDepth(samplingCoord); float3 samplingViewPosition = ReconstructViewPositionFromDepth(samplingCoord, samplingRawDepth); // 現在のviewPositionとoffset済みのviewPositionが一定距離離れていたらor近すぎたら無視 float dist = distance(samplingViewPosition.xyz, viewPosition.xyz); if (dist < _OcclusionMinDistance || _OcclusionMaxDistance < dist) { continue; } // 対象の点のdepth値が現在のdepth値よりも小さかったら遮蔽とみなす(= 対象の点が現在の点よりもカメラに近かったら) if (samplingViewPosition.z > offsetViewPosition.z) { occludedCount++; } } float aoRate = (float)occludedCount / (float)divCount; // NOTE: 本当は環境光のみにAO項を考慮するのがよいが、forward x post process の場合は全体にかけちゃう color.rgb = lerp( baseColor, _OcclusionColor.rgb, aoRate * _OcclusionStrength );
sampling points は c# 側で単位球内にランダムに散らした点群をシェーダーに渡したものです。
static Vector4[] GetRandomPointsInUnitSphere() { var points = new List<Vector4>(); while (points.Count < SAMPLING_POINTS_NUM) { var p = UnityEngine.Random.insideUnitSphere; points.Add(new Vector4(p.x, p.y, p.z, 0)); } return points.ToArray(); }
2. StarCraft II の SSAO(半球サンプリング)

全球サンプリングには無駄な部分があります。それは、法線方向の反対側はジオメトリの内側になっている可能性が高い点です。
そこでサンプリングする点を法線方向を考慮した半球に限定することにより最適化を進めた計算方法になります。
方法は全球サンプリングとほぼ変わりません。サンプルする対象の点が半球内になっただけです。
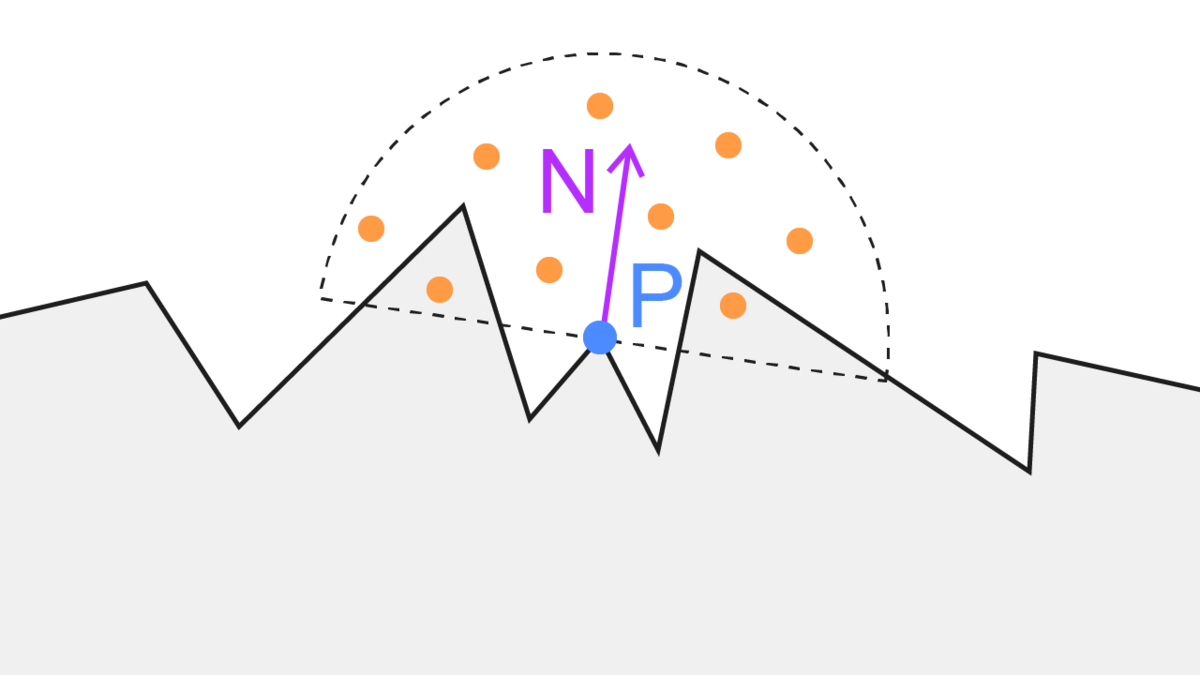
- depth buffer を元に、これから描画する点 P のビュー座標系における位置を求める
- 点 P から、法線方向の半球内のランダムな点 S のビュー座標を計算
- 点 S の深度値(Sz)と、カメラから見た S の位置の depth buffer の深度値(Sd)を比較
- Sd > Sz なら点 S は遮蔽されているとみなす
- 1~4を指定したサンプル数繰り返し、遮蔽率を計算
利点はサンプリング回数の無駄が減ったことです。
欠点は法線方向への考慮が必要なので法線情報が格納されたテクスチャが必要になる点です。
Deferred Rendering を使う場合はほとんどの場合で G-Buffer に法線を含めているはずなので「どう用意するか」に関しては特に気にする必要はないのですが Forward Rendering の場合は一工夫必要です。
幸い、Unityには DepthTextureMode で法線が入ったテクスチャを焼くように指定することができます。
camera.depthTextureMode |= DepthTextureMode.DepthNormals;
名前の通り、depthと法線を一つのテクスチャに埋めているようですね。素直に実装すると2パス必要なところ、1パスで2つの情報を入れるようにしてくれているのでこれを使うことにします。
Unity - Scripting API: DepthTextureMode.DepthNormals
以下、該当するc#とシェーダーへのリンクです。
https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Shaders/SSAOHemisphere.shader https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Scripts/SSAOHemisphere.cs
実装を一部抜粋しながら見ていきます。
まず、半球内にランダムに散らした点を生成します。法線方向への考慮はシェーダー内で行います。
static Vector4[] GetRandomPointsInUnitHemisphere() { var points = new List<Vector4>(); while (points.Count < SAMPLING_POINTS_NUM) { var r1 = UnityEngine.Random.Range(0f, 1f); var r2 = UnityEngine.Random.Range(0f, 1f); var x = Mathf.Cos(2 * Mathf.PI * r1) * 2 * Mathf.Sqrt(r2 * (1 - r2)); var y = Mathf.Sin(2 * Mathf.PI * r1) * 2 * Mathf.Sqrt(r2 * (1 - r2)); var z = 1 - 2 * r2; z = Mathf.Abs(z); points.Add(new Vector4(x, y, z, 0)); } return points.ToArray(); }
法線方向の半球内にランダムにオフセットするために、法線を使った正規直交基底内を利用します。法線マップを実装するときの考え方に近いですね。
法線は _CameraDepthNormalsTexture から取得します。
オフセットする位置を計算したらあとは全球サンプリングと同じ方法になります。
TEXTURE2D_SAMPLER2D(_CameraDepthNormalsTexture, sampler_CameraDepthNormalsTexture); ... float3 SampleViewNormal(float2 uv) { float4 cdn = SAMPLE_TEXTURE2D(_CameraDepthNormalsTexture, sampler_CameraDepthNormalsTexture, uv); return DecodeViewNormalStereo(cdn) * float3(1., 1., 1.); } ... float3x3 GetTBNMatrix(float3 viewNormal) { float3 tangent = float3(1, 0, 0); float3 bitangent = float3(0, 1, 0); float3 normal = viewNormal; float3x3 tbn = float3x3(tangent, bitangent, normal); return tbn; } ... float3 viewNormal = SampleViewNormal(i.texcoord); ... for (int j = 0; j < SAMPLE_COUNT; j++) { float3 offset = _SamplingPoints[j]; offset.z = saturate(offset.z + _OcclusionBias); offset = mul(GetTBNMatrix(viewNormal), offset); ...
3. UE4 の SSAO(Angle Based)
SIGGRAPH2012でUE4のデモに関する発表の中で紹介された手法です。
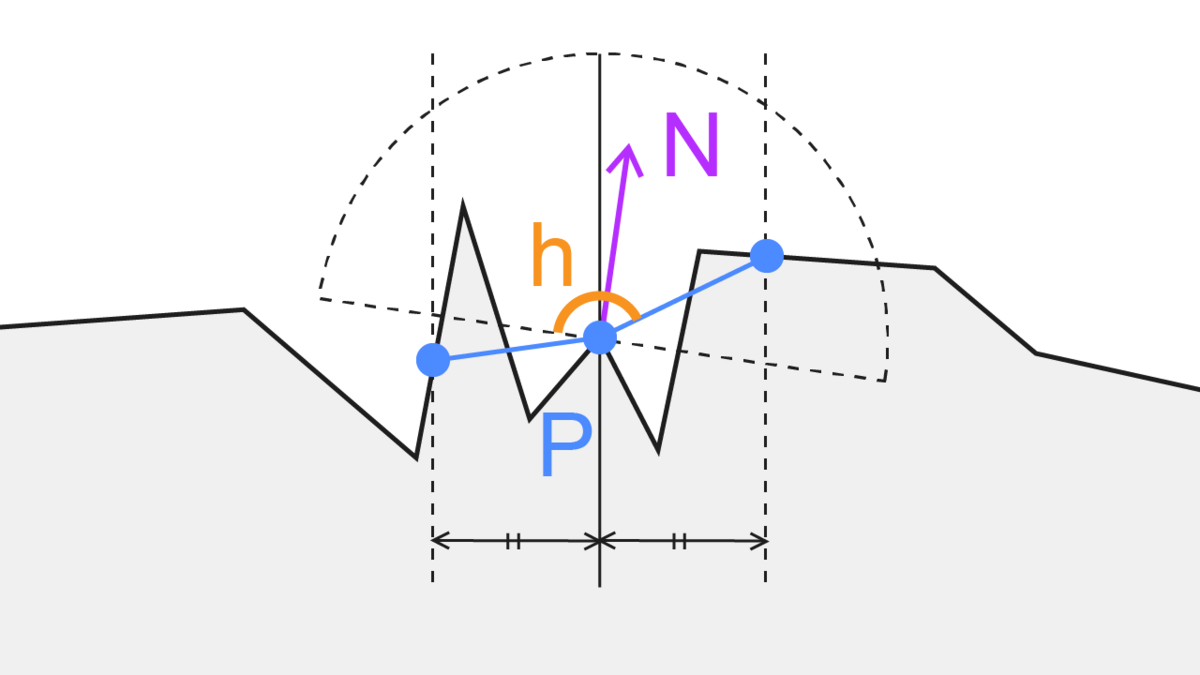
「とある点Pから等距離に伸ばした2点」の位置を計算し、「とある点Pと2点のそれぞれの角度の合計」で遮蔽具合を判断する、という方法です。サンプリング数は6x2で12点を必要としているようです。
つまり、「角度6種と長さ6種の設定」が鍵になります。これをいい具合にばらけさせるなど調整する必要があります。
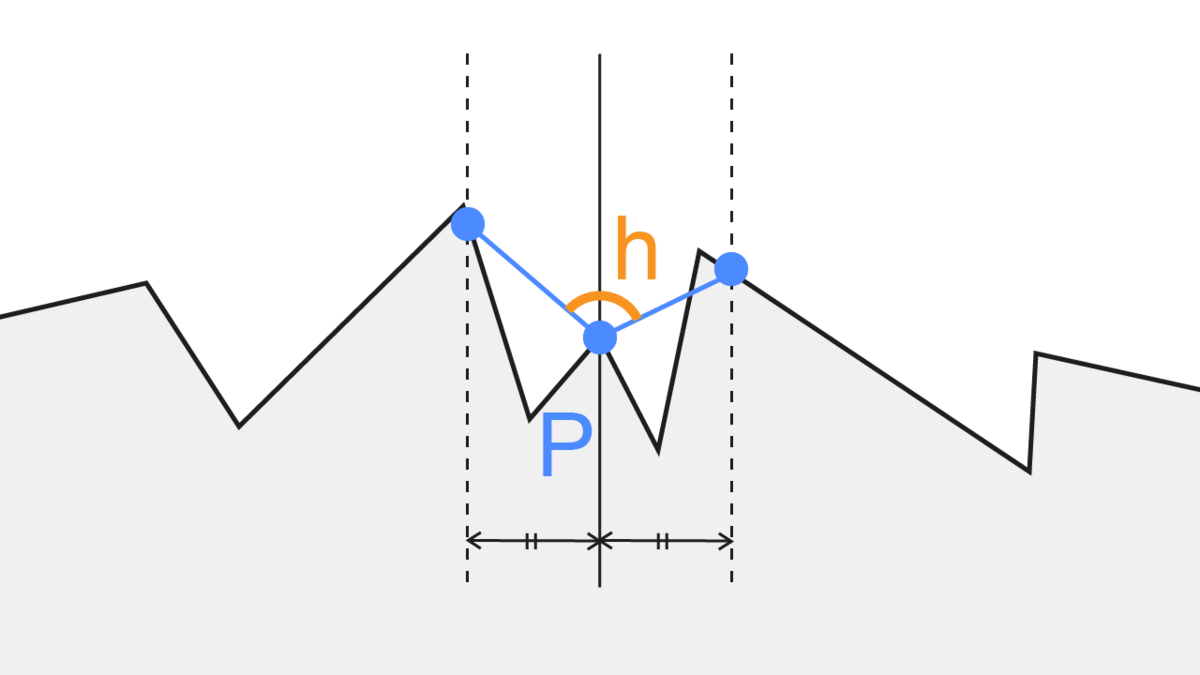
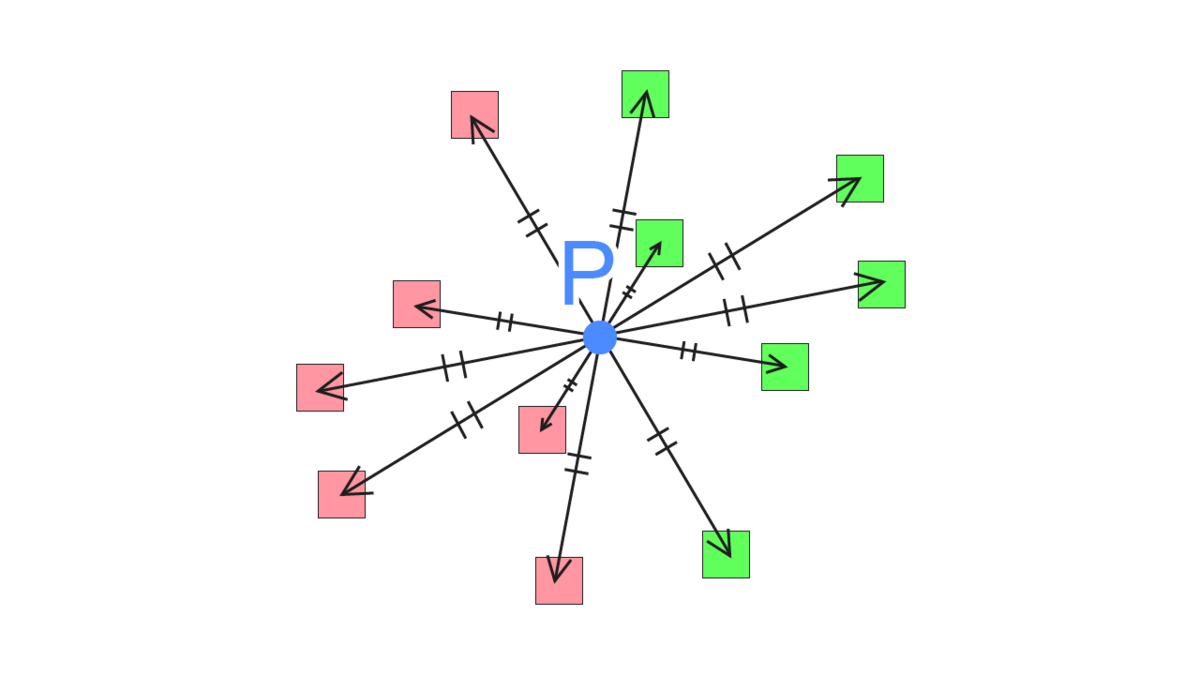
この方法の利点は、AmbientOcclusionの計算に使うテクスチャのサンプル数が最低12回で済むという点です。全球を考慮した方法と比べると大きな差ですね。また、角度を遮蔽度合いとして捉えることができます。つまり、全球/半球サンプリングでは各サンプリング点において「遮蔽されているかどうか」しか判別できなかったのが、「角度の累積でどれぐらい遮蔽されているかの度合い」を考えることができるのでより近い近似になりそうです。また、サンプリング位置をできるだけ散らすために4x4pxの範囲内でさらに回転を加えているようですね。
サンプル数が「最低12回」と書いたのは、ピクセルベースの法線情報(ex. G-Bufferの法線情報やノーマルマップ)を考慮するかどうかでサンプル数が変わるからです。スライドによると法線を考慮したいケースでは法線情報をもとに範囲を限定しつつさらにもう一回遮蔽度合いの計算を行うようです。そのため、サンプル数は計24回になりますね。
(2023.7.17修正) 上の法線方向を考慮した実装に関して改めて資料を読んでいたところ法線を踏まえつつ再度遮蔽度具合の計算を行うのではなく、法線の半球の裏側を隠れているとみなしてclampした角度をAO項の計算に使う、ということのようでした。
以下、該当するc#とシェーダーへのリンクです。
https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Shaders/SSAOAngleBased.shader https://github.com/takumifukasawa/UnitySSAOBuiltinPipeline/blob/master/SSAO_BuiltinPipeline/Assets/Scripts/SSAOAngleBased.cs
実装を一部抜粋しながら見ていきます。
まず、c#でサンプリングする角度と距離を6つずつ作成します。
スライドでは角度と長さの情報をテクスチャで渡しているのか、Uniformな配列情報として渡しているのかがわかりませんでした。デモではUniformな配列情報として渡すことにします。
ランタイム実行の度に生成しているのですが、毎回良質なサンプリング点を生成できるとは限らないので、あらかじめ任意の点を設定できるようにする方が実際はよいと思います。
var rotList = new List<float>(); var lenList = new List<float>(); var sampleCount = 6; for (int i = 0; i < sampleCount; i++) { // 任意の角度. できるだけ均等にバラけていた方がよい var pieceRad = (Mathf.PI * 2) / sampleCount; var rad = UnityEngine.Random.Range( pieceRad * i, pieceRad * (i + 1) ); rotList.Add(rad); // 任意の長さの範囲. できるだけ均等にバラけていた方がよい var baseLen = 0.1f; var pieceLen = (1f - baseLen) / sampleCount; var len = UnityEngine.Random.Range( baseLen + pieceLen * i, baseLen + pieceLen * (i + 1) ); lenList.Add(len); } sheet.properties.SetFloatArray("_SamplingRotations", rotList.ToArray()); sheet.properties.SetFloatArray("_SamplingDistances", lenList.ToArray());
「とある点Pから等距離に伸ばした2点」の位置を計算し、「とある点Pと2点のそれぞれの角度の合計」で遮蔽具合を判断する計算はこちらになります。
スライドやいろいろな記事を見ると2次元的に角度を計算しているようにみえる(おそらくxyのどちらかの次元を落としている)のですが、自分の実装ではビュー座標系において3次元的に角度を計算しています。
float occludedAcc = 0.; int samplingCount = 6; for (int j = 0; j < samplingCount; j++) { float2x2 rot = GetRotationMatrix(_SamplingRotations[j]); float offsetLen = _SamplingDistances[j] * _OcclusionSampleLength; float3 offsetA = float3(mul(rot, float2(1, 0)), 0.) * offsetLen; float3 offsetB = -offsetA; float rawDepthA = SampleRawDepthByViewPosition(viewPosition, offsetA); float rawDepthB = SampleRawDepthByViewPosition(viewPosition, offsetB); float depthA = Linear01Depth(rawDepthA); float depthB = Linear01Depth(rawDepthB); float3 viewPositionA = ReconstructViewPositionFromDepth(i.texcoord, rawDepthA); float3 viewPositionB = ReconstructViewPositionFromDepth(i.texcoord, rawDepthB); float distA = distance(viewPositionA, viewPosition); float distB = distance(viewPositionB, viewPosition); if (abs(depth - depthA) < _OcclusionBias) { continue; } if (abs(depth - depthB) < _OcclusionBias) { continue; } if (distA < _OcclusionMinDistance || _OcclusionMaxDistance < distA) { continue; } if (distB < _OcclusionMinDistance || _OcclusionMaxDistance < distB) { continue; } float3 surfaceToCameraDir = -normalize(viewPosition); float dotA = dot(normalize(viewPositionA - viewPosition), surfaceToCameraDir); float dotB = dot(normalize(viewPositionB - viewPosition), surfaceToCameraDir); float ao = (dotA + dotB) * .5; occludedAcc += ao; } float aoRate = occludedAcc / (float)samplingCount;
今回、遮蔽の度合いはこのように -1 ~ 1 の範囲と捉えて計算しています。プロジェクトごとに調整してよい部分かなと思います。例えば「ちょっとでも角度があったら遮蔽しているとみなしたい」時は 0 ~ 1 の範囲の方が適切です。
float ao = (dotA + dotB) * .5; occludedAcc += ao;
品質を高めたい場合はサンプリング回数を増やしてもよいと思います。作っているものによっては描画処理に余裕がある場合などですね。
実装の改善として、角度と長さはfloatの配列でそれぞれ要素数6になっていますがvector2な配列で[0]に角度, [1]に長さを入れ vector2の要素数6の配列にすると送る配列が一つ減るので節約になりそうですね。
参考
https://zenn.dev/mebiusbox/articles/c7ea4871698ada
https://ambientocclusion.hatenablog.com/entry/2013/11/07/152755
https://marina.sys.wakayama-u.ac.jp/~tokoi/?date=20101122
https://developers.wonderpla.net/entry/2014/01/31/151540
https://inzkyk.xyz/ray_tracing_in_one_weekend/week_3/3_7_generating_random_directions/
【WebGL】GLTFのUV座標系の向きについて
GLTFのUV座標系について知識不足だったので、メモを残しておきたいと思います。
結論、GLTF自体のフォーマットでは以下の図のようにUV座標は左上が原点(左上が(0,0)で右下が(1,1))に設定されています。
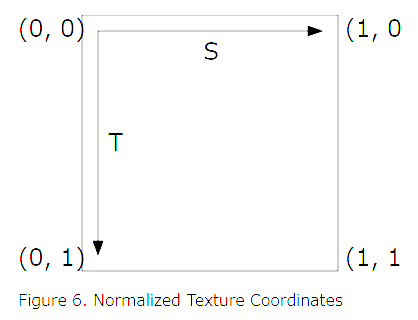
※画像は下記URLの図をスクショしたもの
普段html,jsを触っている感覚からすると自然な感覚かなと思います。
しかし、「あえてWebGLのUVの原点が左下になるように設計・実装している」場合には問題が発生します。具体的には、gl.pixelStorei(gl.UNPACK_FLIP_Y_WEBGL, true); を呼んでいるときです。
まず、画像データを何かしらの方法で読み込む(fetchなど)と座標系の原点は左上になります。
一方、Blenderなどの各種DCCツールでは以下のように UVの座標系の原点を左下 にしているケースが大半だと思います。つまり、Yが反転した状態になっているのです。
(0, 1) ---- (1, 1) | | | | (0, 0) ---- (1, 0)
↓ Blender の UVエディタウインドウのスクショ
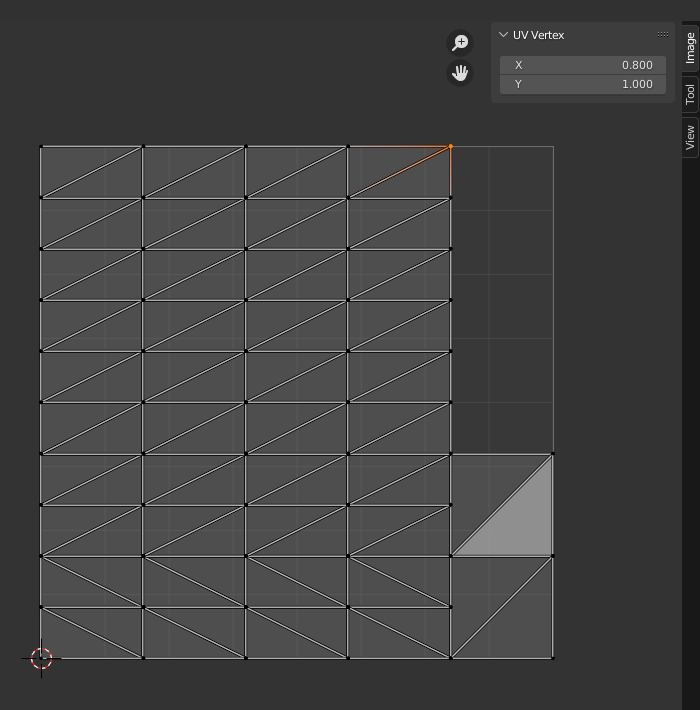
しかし、WebGLでは gl.pixelStorei(gl.UNPACK_FLIP_Y_WEBGL, true); を呼ぶことによって左下を原点とすることができます。
個人的には各種DCCツールに合わせて左下に原点を持ってきた方がわかりやすいと思っていてこの UNPACK... の指定は入れるようにしているのですが、GLTFをパースしているときに「UVのY軸がなぜか逆だな」と思って調べてみると、そもそもGLTFでは左上が原点になっていた、と気がついた経緯でした。
最終的には以下のような実装にまとまりました。
- 左下を原点とするために
gl.pixelStorei(gl.UNPACK_FLIP_Y_WEBGL, true);は指定する - GLTFからUVを読み込む際、Yを反転させてからBufferにデータを送る
【WebGL】CubeMap(環境マップ)の軸について整理する
生のWebGLを書いているときにCubeMap(環境マップ)がサンプルされる軸についてややこしくなったので整理したいと思います。
具体的には、WebGL2においてCubeMapの色を取得するために texture(samplerCube, vec3) で呼び出す際、
「どうサンプルされるのが正しいのか」「渡したベクトルに対してCubeMapのどの軸がサンプルされるか?」というような内容になります。
skyboxも実装したサンプル図です(skyboxそのものの実装については割愛します)

こちらは開発中のWebGLの自作ライブラリになるのですが動作デモになります。
https://takumifukasawa.github.io/PaleGL/workspace/011_cube-mapping/
目次
CubeMapの考え方
この画像のように、シェーダー内ではカメラから物体の表面に対して、法線を軸に反射させたベクトルを使うのが基本的な考え方です。
映り込み(specular)に使うと、画像から色をサンプルしているかつ視点によってサンプルする色も変化するので情報量が増します。(ex. UnityのReflectionProbeや、Skyboxのreflection成分)
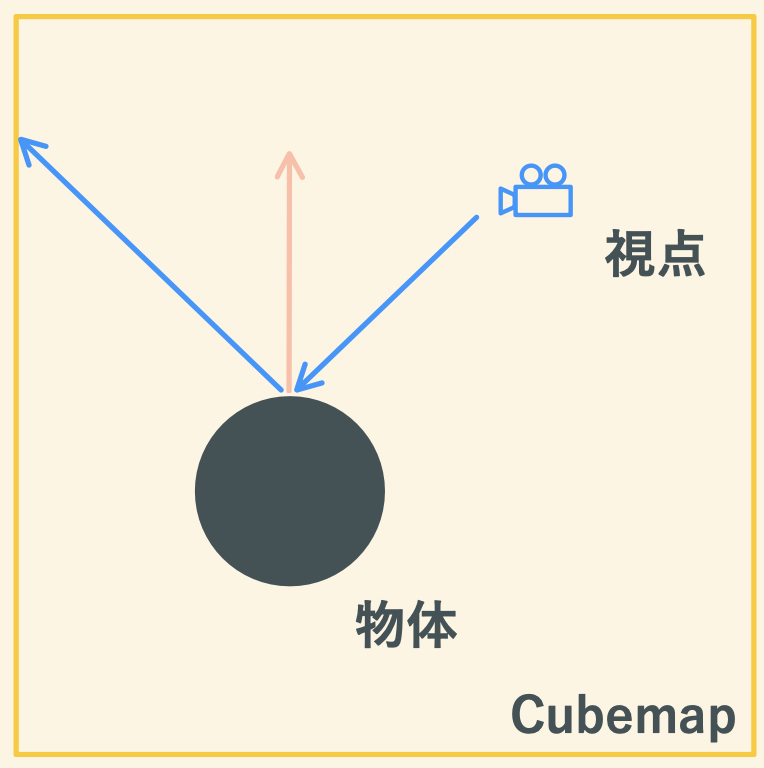
WebGLのAPIも踏まえた具体的な説明はこちらがとてもわかりやすいです。
wgld.org | WebGL: キューブ環境マッピング |
サンプルするベクトルを変えながら確認
以下のような状態で、球体を置いてCubeMappingを実装していきます。
- 球体に出力する色はCubeMappingからサンプルした色をそのまま出す
- js側(各種行列など)は右手座標系で実装。z+が手前
- 球体の位置は(0,0,0)。カメラの位置は(0,0,5)で球体を向く。つまり-zを向く状態。
- CubeMapに使う6面の画像は+x,-x,+y,-y,+z,-zが分かるような画像

1. reflectしたものをそのまま使う
// PtoE ... 描画する点のワールド座標 -> カメラのワールド座標 の正規化ベクトル // N ... 正規化した法線 vec3 reflectDir = reflect(-PtoE, N); vec3 cubeColor = texture(uCubeTexture, reflectDir).xyz;

どうやら軸は手前がz+になっているようです。しかし、「反転して鏡のように映る」期待は逆の結果になります。
CubeMapの軸
このサイトによると、CubeMapの参照する軸についてこう書かれています。
Pragmatic physically based rendering : HDR
Cubemaps spec comes from the time when RenderMap ruled the world and Renderman it's using Left-Handed Coordinate system so do the cubemaps. That means to we will need to flip the X axis in our shader whenever we sample from a CubeMap texture. Additionally you will need to point your camera towards +Z instead of the usual -Z in order to start at expected direction. Otherwise you might end up looking at the wall like in case of the Pisa texture we are using.
どうやら、CubeMapはRenderMap(Autodesk製のソフト?ツール?)にならって左手座標系を基準としているようです。
しかしWebGLは右手座標系で設計されている(ポリゴンの正面判定など)ので、参照する軸が異なります。
つまりCubeMapの考え方に沿って左手座標系に沿って実装するためには、まずx軸を反転する必要があり、場合によってはz軸も反転する必要がある、ということのようです。
(↑ 解釈が間違っていたらすいません)
試しにx軸を反転させてみます。
2. reflect & x軸を反転
// PtoE ... 描画する点のワールド座標 -> カメラのワールド座標 の正規化ベクトル // N ... 正規化した法線 vec3 reflectDir = reflect(-PtoE, N); reflectDir.x *= -1.; vec3 cubeColor = texture(uCubeTexture, reflectDir).xyz;
z+が手前、x+が左側になりました。両方反転させると左手座標系になるので、180度回転をさせます。
3. reflect & x軸を反転 & xzを180度回転
// PtoE ... 描画する点のワールド座標 -> カメラのワールド座標 の正規化ベクトル // N ... 正規化した法線 mat2 rotate(float r) { float c = cos(r); float s = sin(r); return mat2(c, s, -s, c); } vec3 reflectDir = reflect(-PtoE, N); reflectDir.x *= -1.; reflectDir.xz *= rotate(3.14); vec3 cubeColor = texture(uCubeTexture, reflectDir).xyz;
手前がz-、右がz+となっています。また、それぞれ反転しているので無事に左手座標系に直りました。
参考
0~1のfloatを32bitRGBAに格納する
デモはこちらにおきました。
デモ https://takumifukasawa.github.io/float-to-rgba-tester/
リポジトリ GitHub - takumifukasawa/float-to-rgba-tester: float to rgba tester

こちらが計算部分のjavascriptのソースになります。
class FloatPacker { static packToRGBA(num) { const rawR = num * 255; const r = Math.floor(rawR); const rawG = (rawR - r) * 255; const g = Math.floor(rawG); const rawB = (rawG - g) * 255; const b = Math.floor(rawB); const rawA = (rawB - b) * 255; const a = Math.floor(rawA); return { r, g, b, a }; } static unpackToFloat({ r, g, b, a }) { return r / 255 + g / (255 * 255) + b / (255 * 255 * 255) + a / (255 * 255 * 255 * 255); } } // usage example const { r, g, b, a } = FloatPackage.packToRGBA(0.87185264); const unpackedFloat = FloatPackage.unpackToFloat({ r, g, b, a });
概要
jpgやpngなど、普段使うことの多いテクスチャの形式ではRGBAの各チャンネルの表現できる値は8bitなので0~255までの256段階になります。
そのため、VATなど頂点シェーダーであらかじめ用意されたデータをテクスチャから読み込んで取り扱うときは、0~255の256段階でしか使うことができません。
しかし、頂点シェーダーでは0.5145や5.4514など、floatな値を使いたい場面があり、256段階では精度が足りないことがほとんどです。
浮動小数点テクスチャを扱うことができればその限りではないのですが、jpgやpngなどの 8bit x 4 = 32bit/pixel なテクスチャの場合は、浮動小数点的をそのままチャンネルに詰めることができません。チャンネルごとに32bitであればもちろんそのまま浮動小数点を入れることができるのですが、8bitだと浮動小数点を入れるにはbit数が足らないからですね。
そのため、浮動小数点をとある変換式にかけることでRGBAの 8bit x 4 の形式に変換し、多少誤差があるものの 8bit x 4 = 32bit/pixel から浮動小数点に直す方法をとることで、浮動小数点を 8bit x 4 = 32bit/pixel な形式のテクスチャに格納することができます。
ただし、0~1の間であることが条件になります。
変換
まず、0.87185264という値があるとします。
この数値に 255 をかけて、整数部分のみ切り出します。 これがRチャンネルに入る要素になります。
0.87185264 * 255 = 222.3224232 => 222
次に、先ほどの小数部分のみを切り出し、再度255をかけて整数部分のみをきりだします。 これがGチャンネルに入る要素になります。
0.3224232 * 255 = 82.217916 => 82
これを残りのB,Aチャンネル分の2回繰り返します。
0.217916 * 255 = 55.56858 => 55 0.56858 * 255 = 144.9879 => 144
最終的に R=222, G=82, B=55, A=144 という数値が得られました。
それでは、0~1の浮動小数点に復元してみましょう これまでは、255をかけて整数部分を切り出すことをしていたので、この逆の計算をしていきます。
(222 / 255) + (82 / (255 ^ 2)) + (55 / (255 ^ 3)) + (144 / (255 ^ 4)) = 0.8718526397663572
最終的に、差分は 0.8718526397663572 - 0.87185264 = -2.336428e-10 となりました。
この程度の差であれば、場面によってはほぼ誤差に近いと捉えることもできそうです。
参考